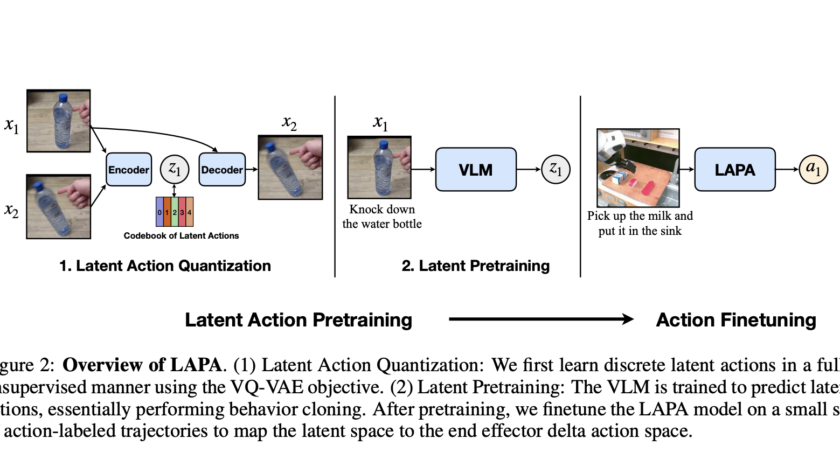
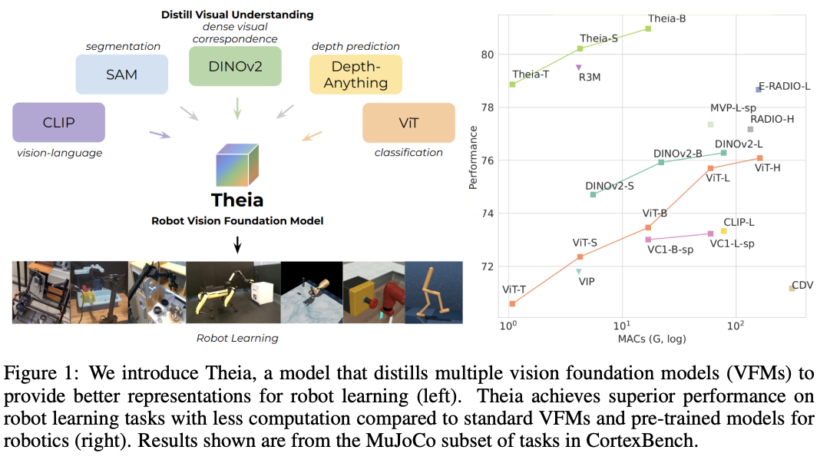
Robots are increasingly being developed for home environments, specifically to enable them to perform daily activities like cooking. These tasks involve a combination of visual interpretation, manipulation, and decision-making across a series of actions. Cooking, in particular, is complex for robots due to the diversity in utensils, varying visual perspectives, and frequent omissions of intermediate…