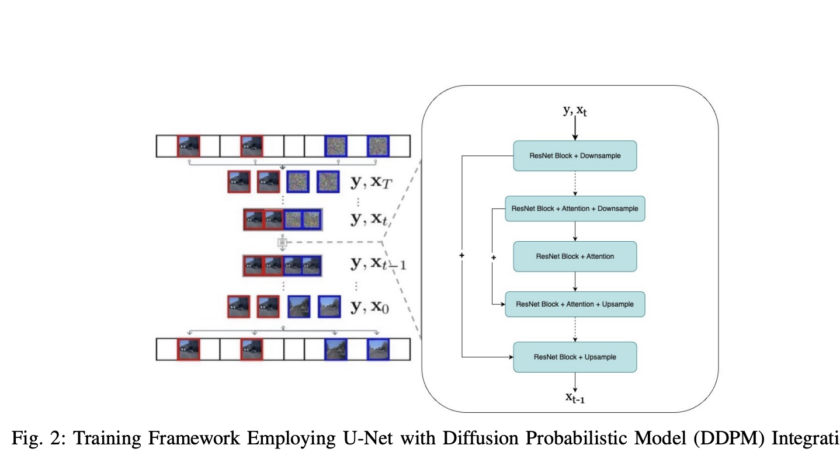
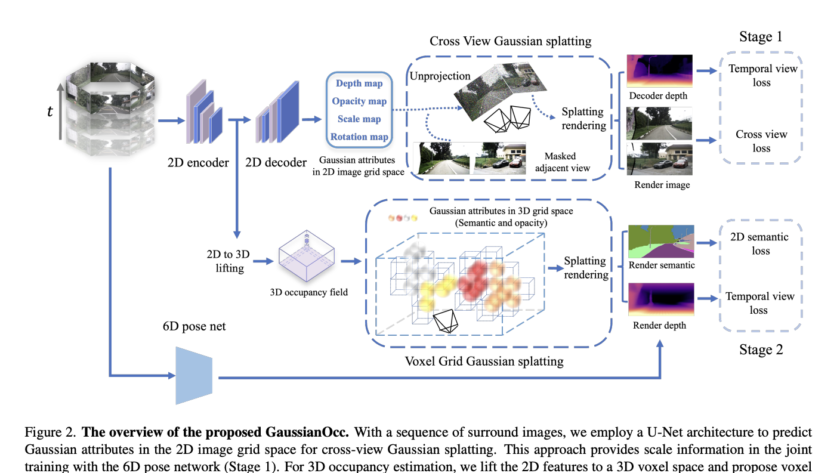
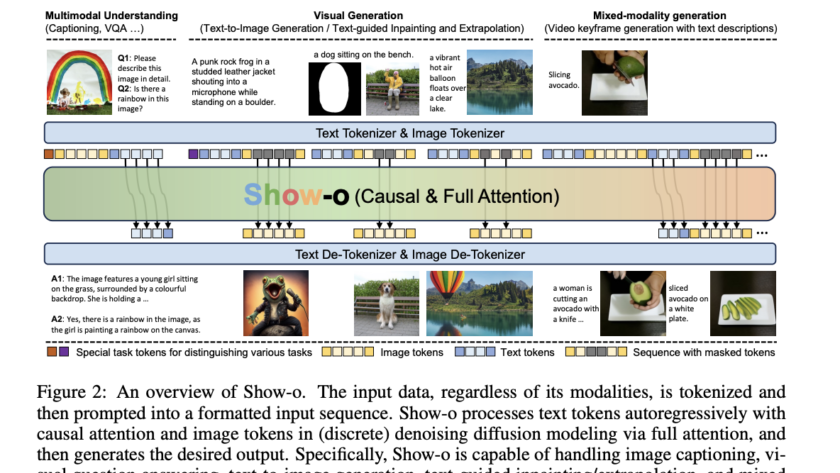
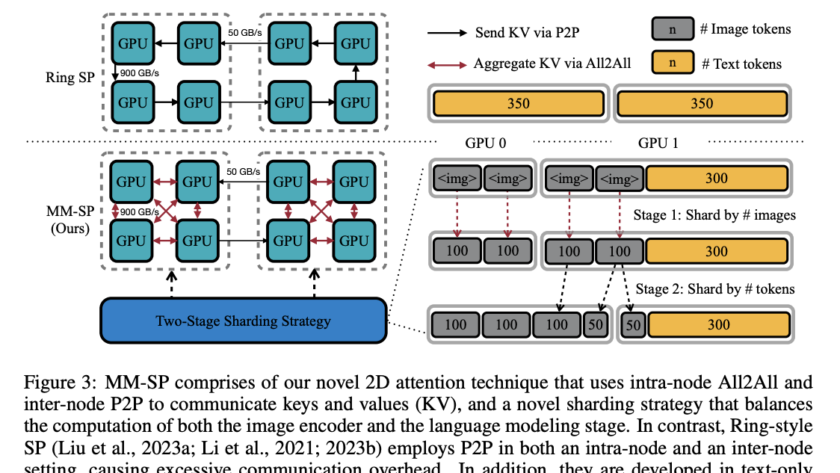
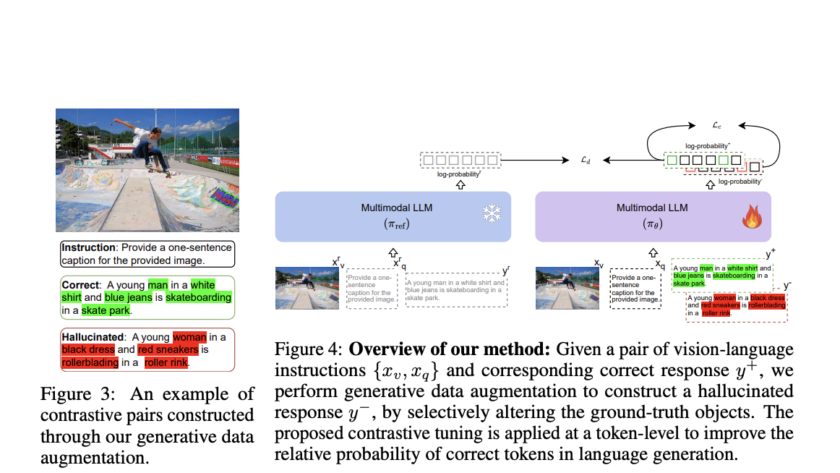
Integrating advanced predictive models into autonomous driving systems has become crucial for enhancing safety and efficiency. Camera-based video prediction emerges as a pivotal component, offering rich real-world data. Content generated by artificial intelligence is presently a leading area of study within the domains of computer vision and artificial intelligence. However, generating photo-realistic and coherent videos…