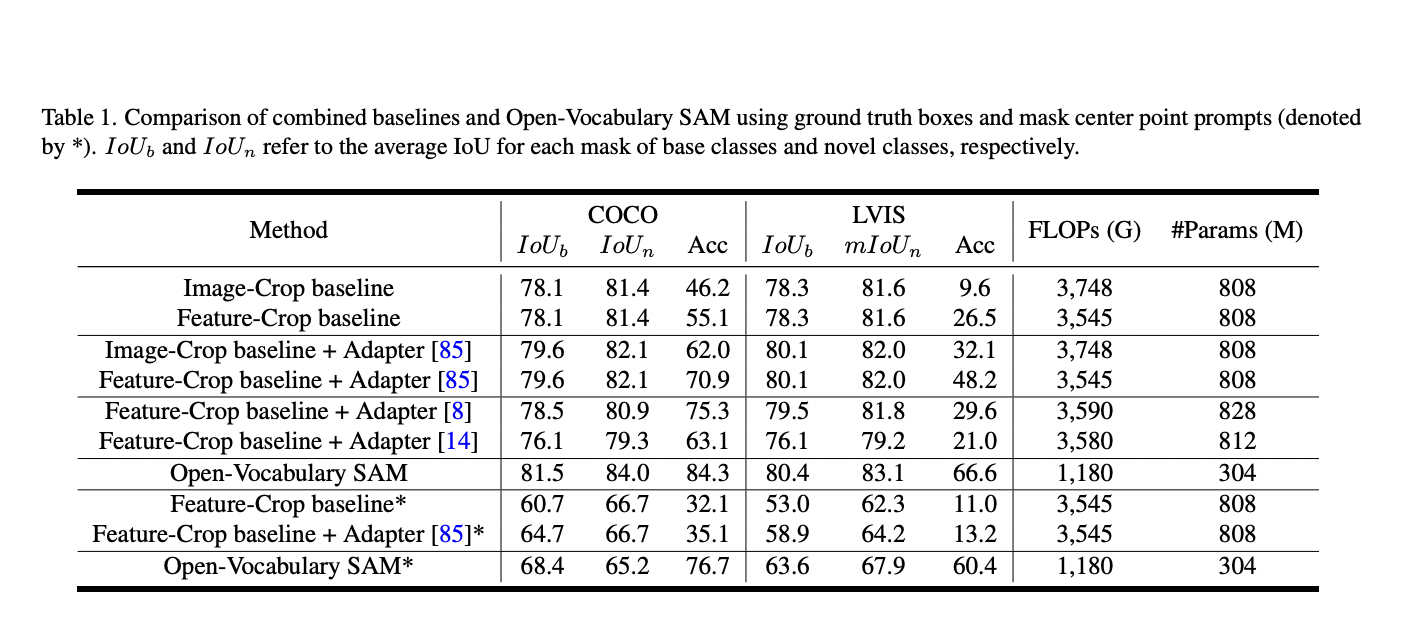
Combining CLIP and the Segment Anything Model (SAM) is a groundbreaking Vision Foundation Models (VFMs) approach. SAM performs superior segmentation tasks across diverse domains, while CLIP is renowned for its exceptional zero-shot recognition capabilities.
While SAM and CLIP offer significant advantages, they also come with inherent limitations in their original designs. SAM, for instance, cannot…