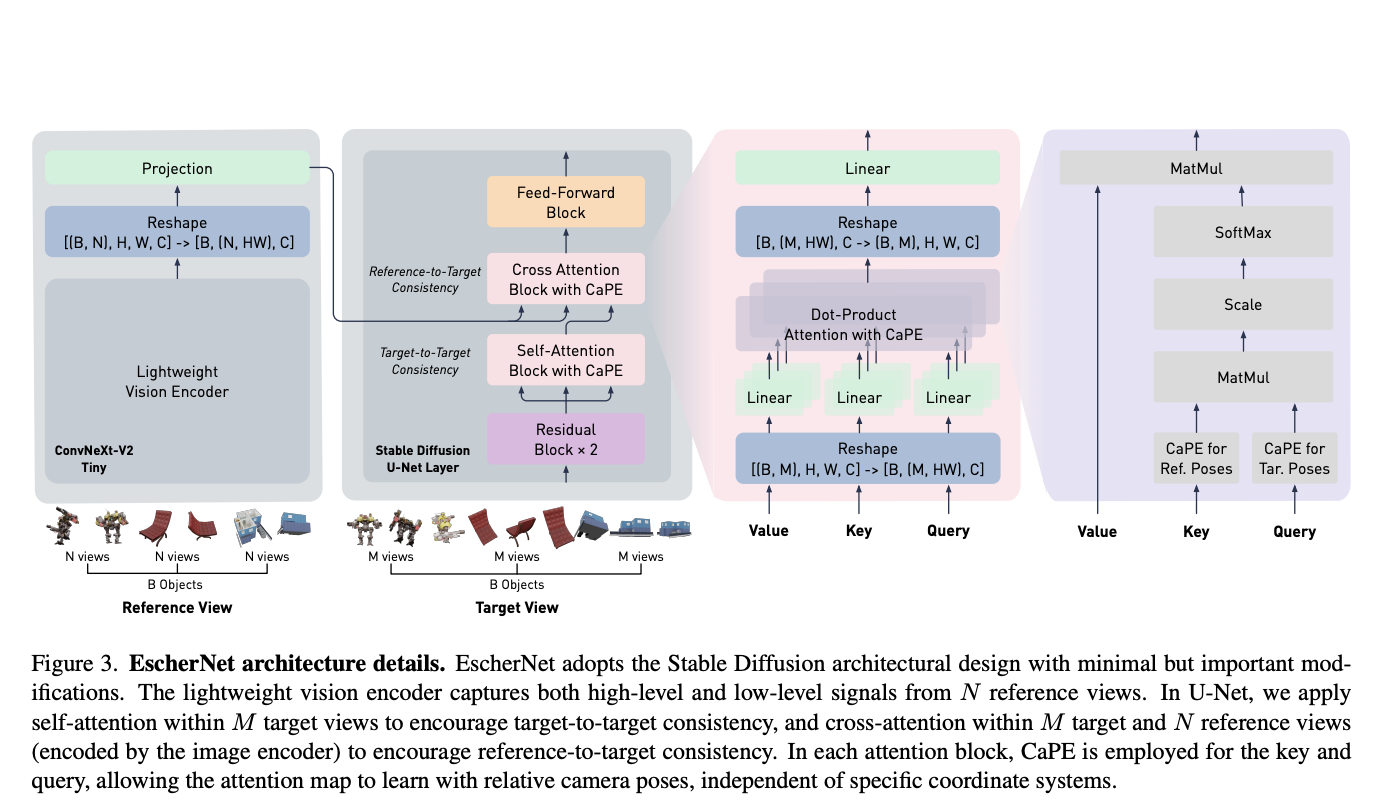
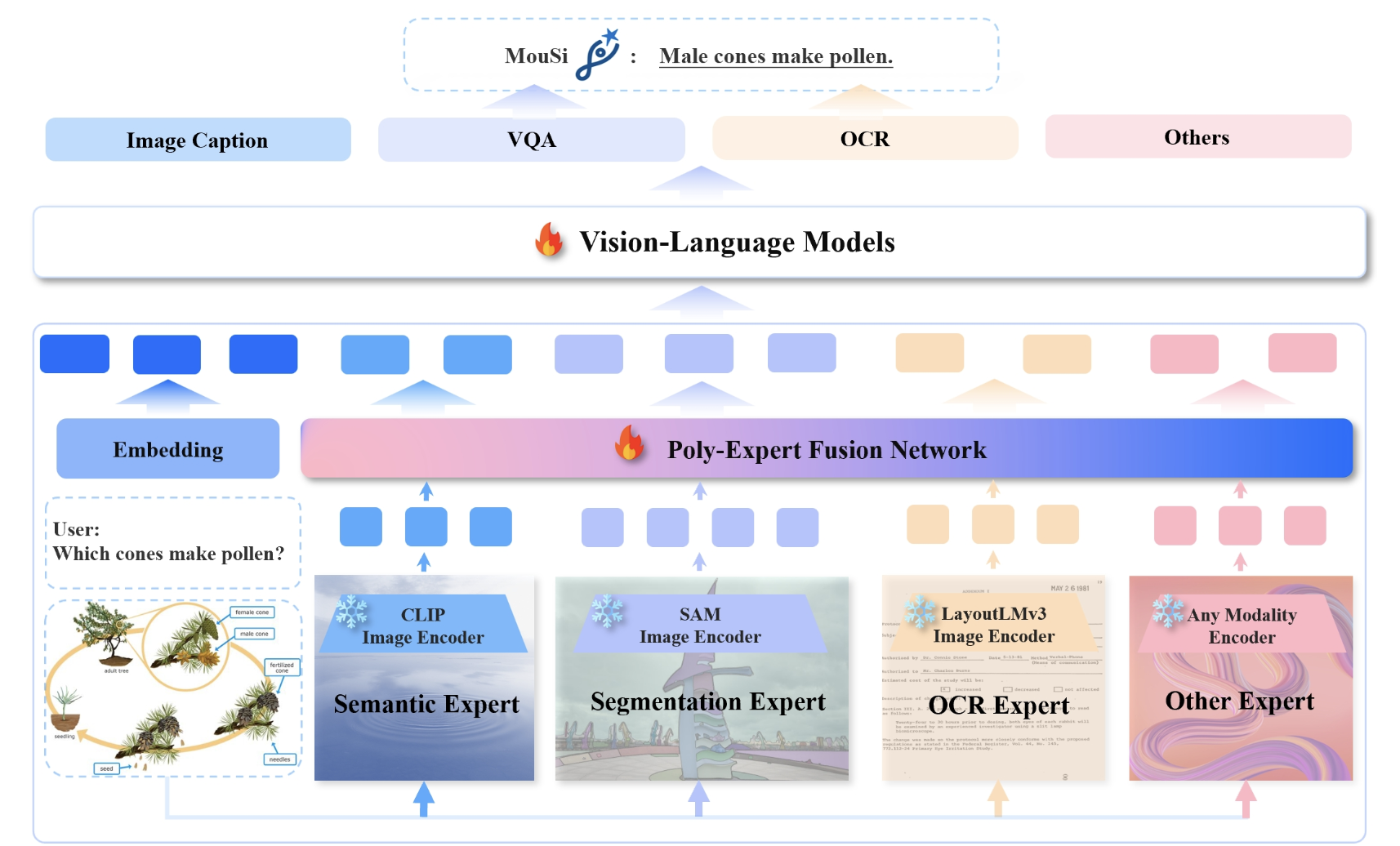
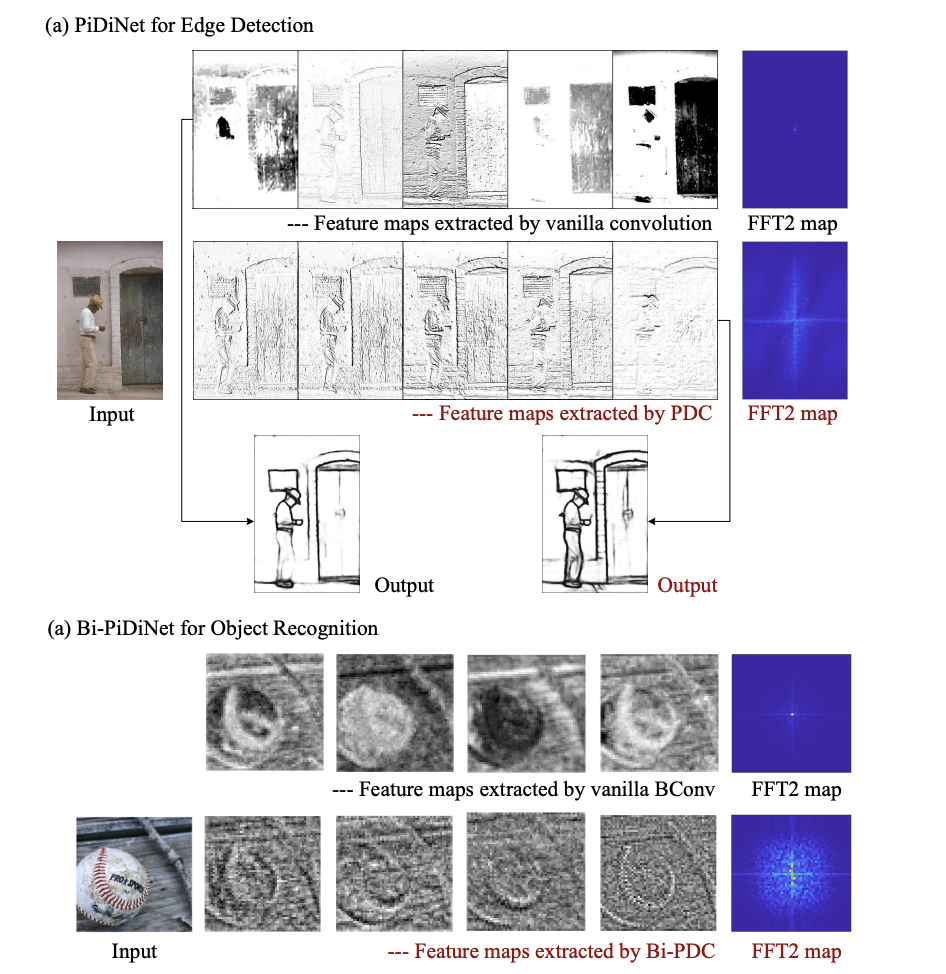
The emergence of Multimodality Large Language Models (MLLMs), such as GPT-4 and Gemini, has sparked significant interest in combining language understanding with various modalities like vision. This fusion offers potential for diverse applications, from embodied intelligence to GUI agents. Despite the rapid development of open-source MLLMs like BLIP and LLaMA-Adapter, their performance could be improved…