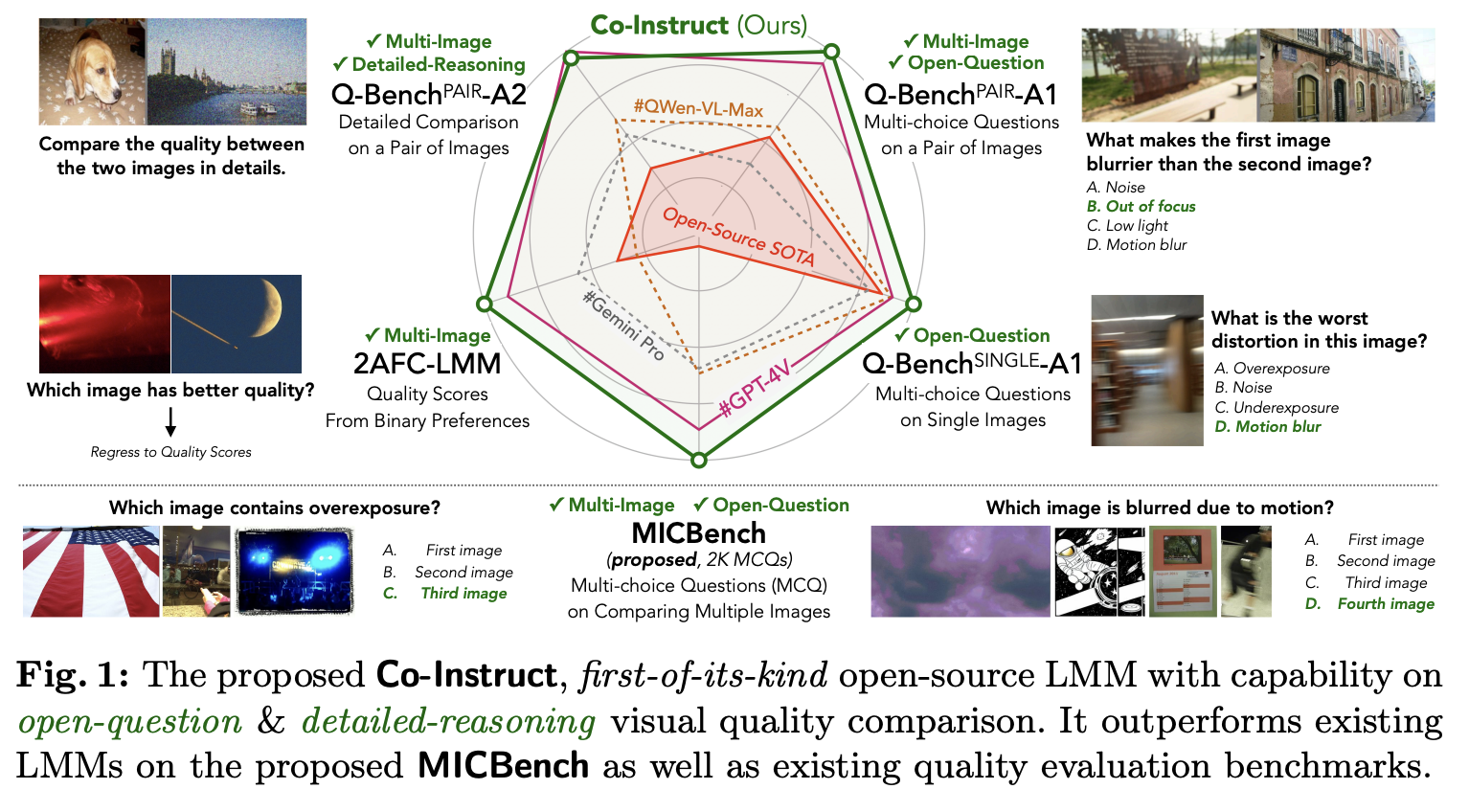
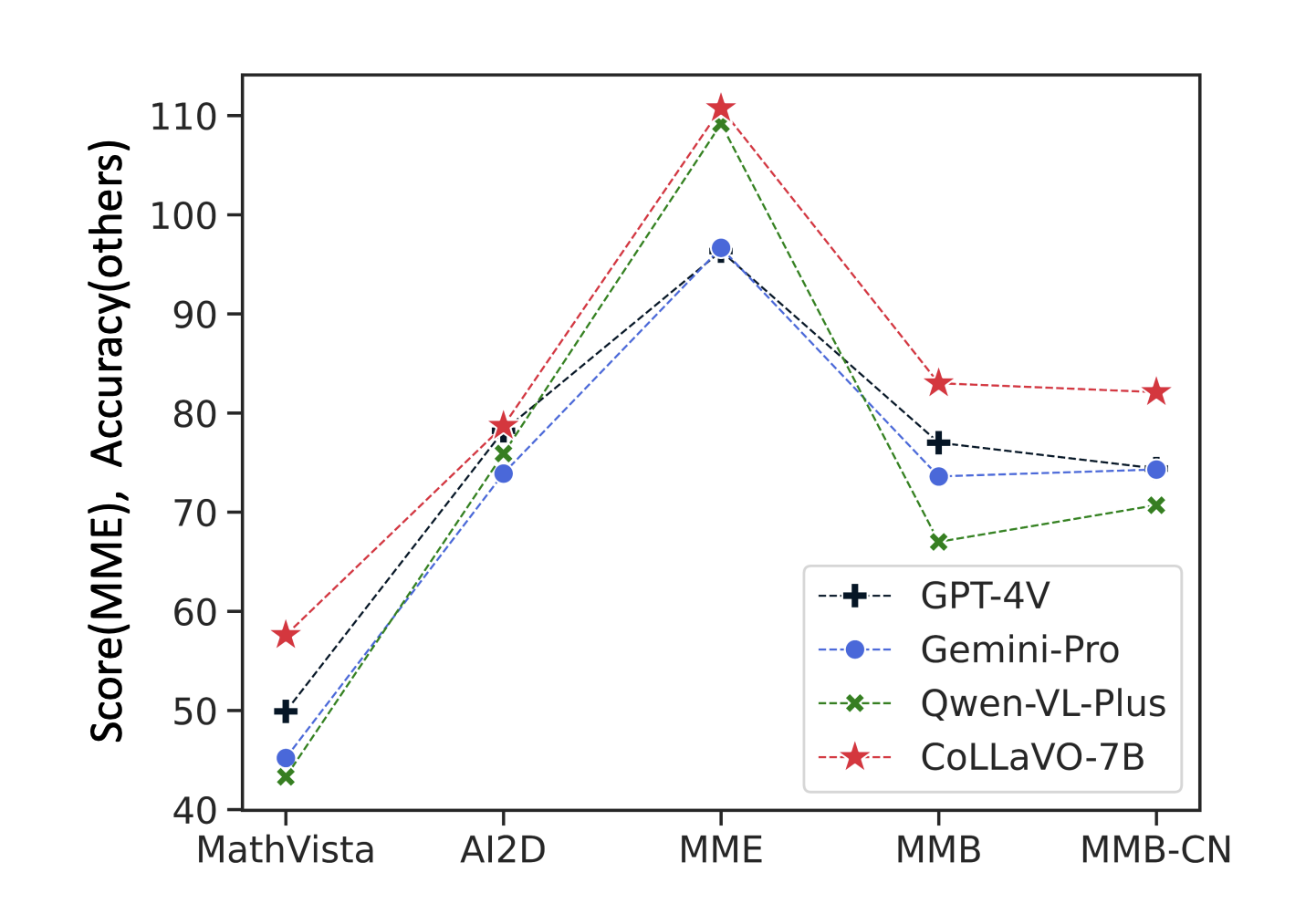
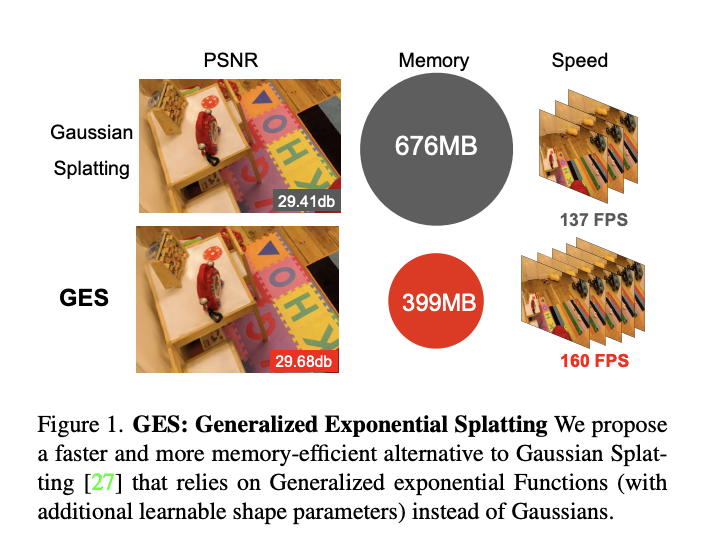
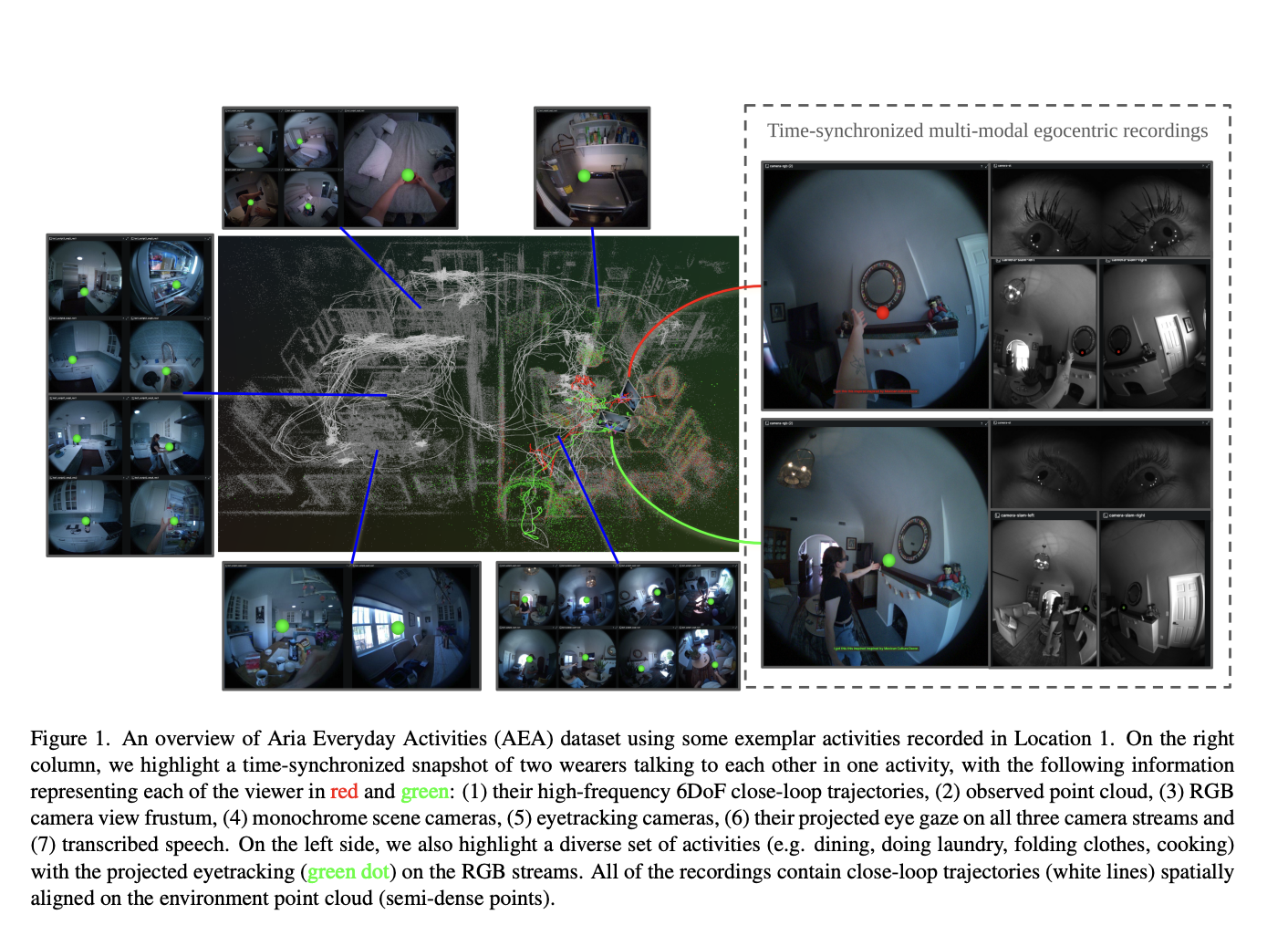
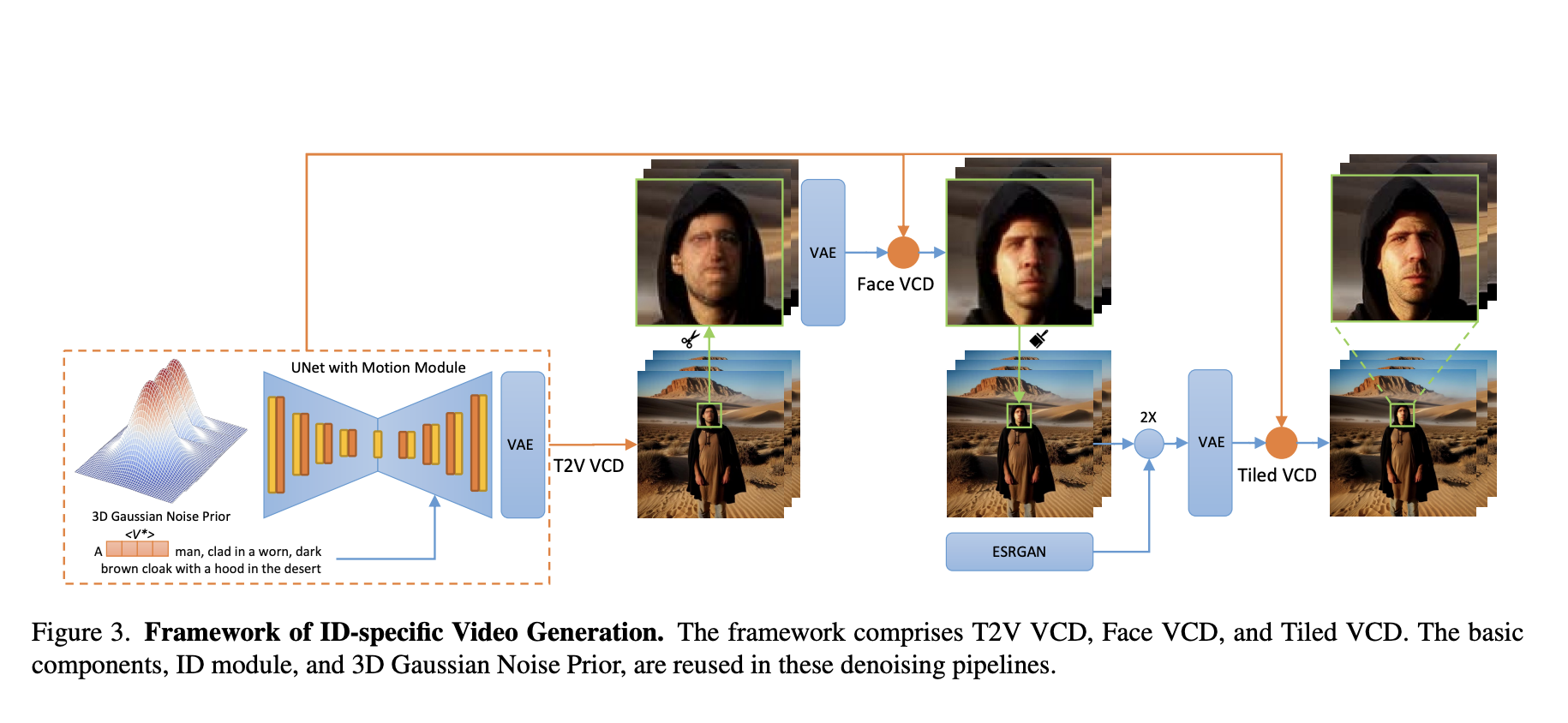
Image Quality Assessment (IQA) is a method that standardizes the evaluation criteria for analyzing different aspects of images, including structural information, visual content, etc. To improve this method, various subjective studies have adopted comparative settings. In recent studies, researchers have explored large multimodal models (LMMs) to expand IQA from giving a scalar score to open-ended…