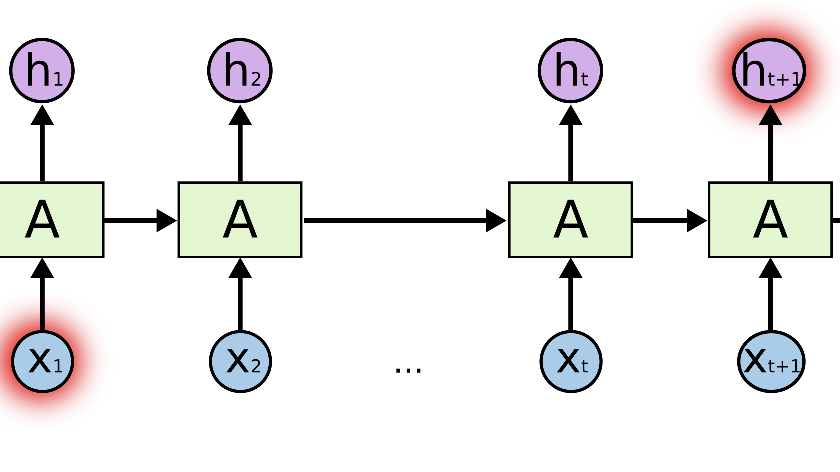
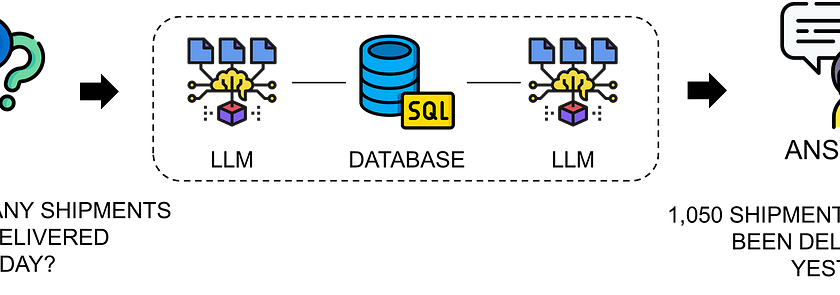
LLMs have shown impressive capabilities in reasoning tasks like Chain-of-Thought (CoT), enhancing accuracy and interpretability in complex problem-solving. While researchers are extending these capabilities to multi-modal domains, videos present unique challenges due to their temporal dimension. Unlike static images, videos require understanding dynamic interactions over time. Current visual CoT methods excel with static inputs but…