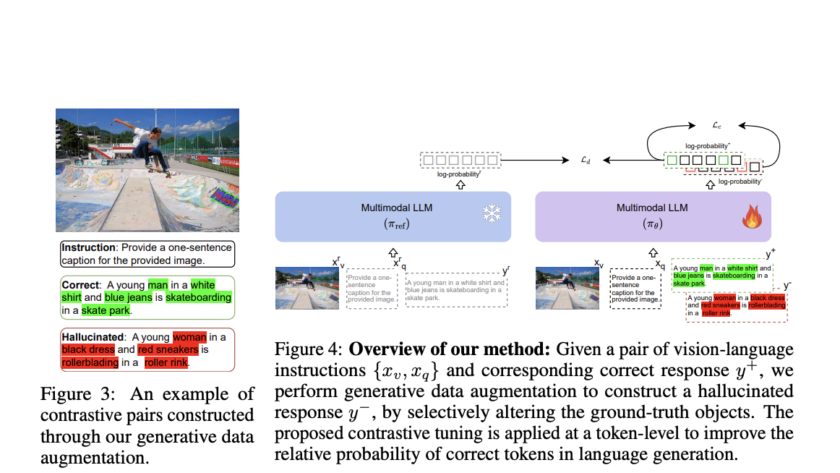
Vision-language models (VLMs) have gained significant attention due to their ability to handle various multimodal tasks. However, the rapid proliferation of benchmarks for evaluating these models has created a complex and fragmented landscape. This situation poses several challenges for researchers. Implementing protocols for numerous benchmarks is time-consuming, and interpreting results across multiple evaluation metrics becomes…