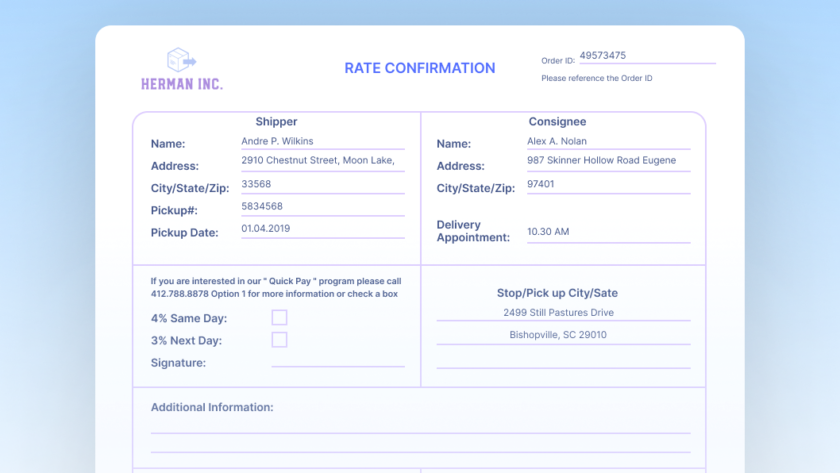
Managing and reviewing contracts throughout their lifecycle is quite a challenging task for businesses. Especially since contract data is often scattered across different systems or departments - making it hard to get a quick comprehensive view of contractual obligations. Consider the volume of contracts that businesses typically deal with, the effort required to manually review…