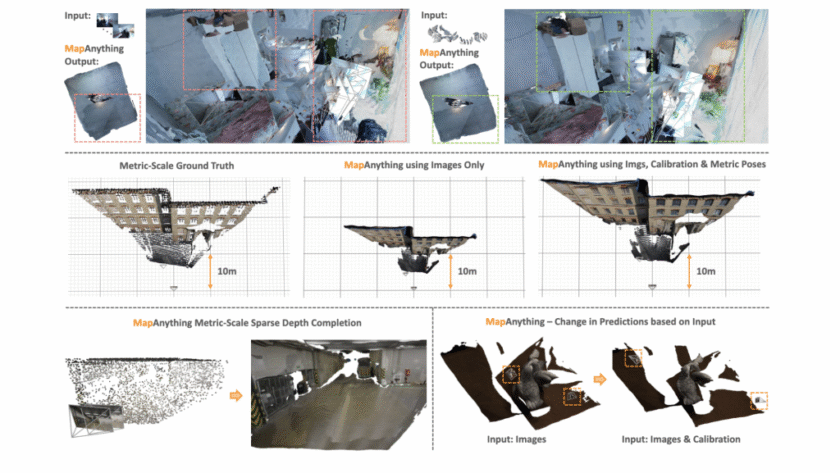
Image by Author
# Introduction
There are numerous tools for processing datasets today. They all claim — of course they do — that they’re the best and the right choice for you. But are they? There are two main requirements these tools should satisfy: they should easily perform everyday data analysis operations and…