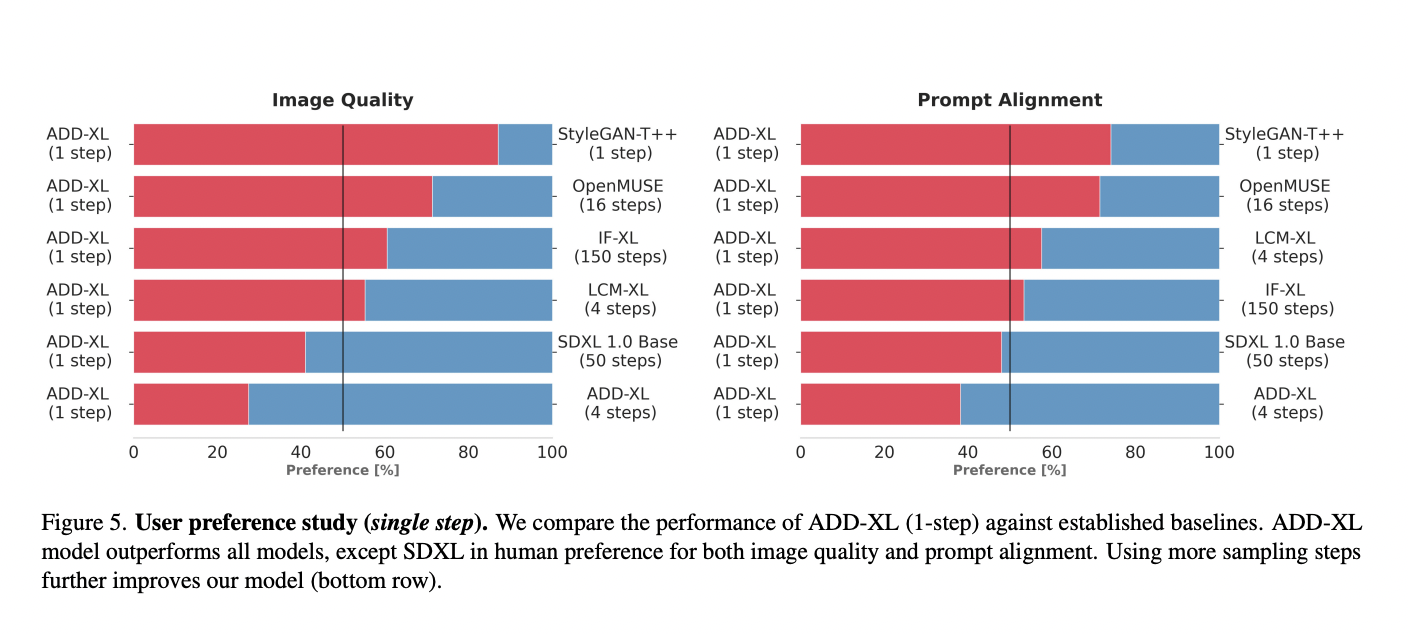
In generative modeling, diffusion models (DMs) have assumed a pivotal role, facilitating recent progress in producing high-quality picture and video synthesis. Scalability and iterativeness are two of DMs’ main advantages; they enable them to do intricate tasks like picture creation from free-form text cues. Unfortunately, the many sample steps required for the iterative inference process…