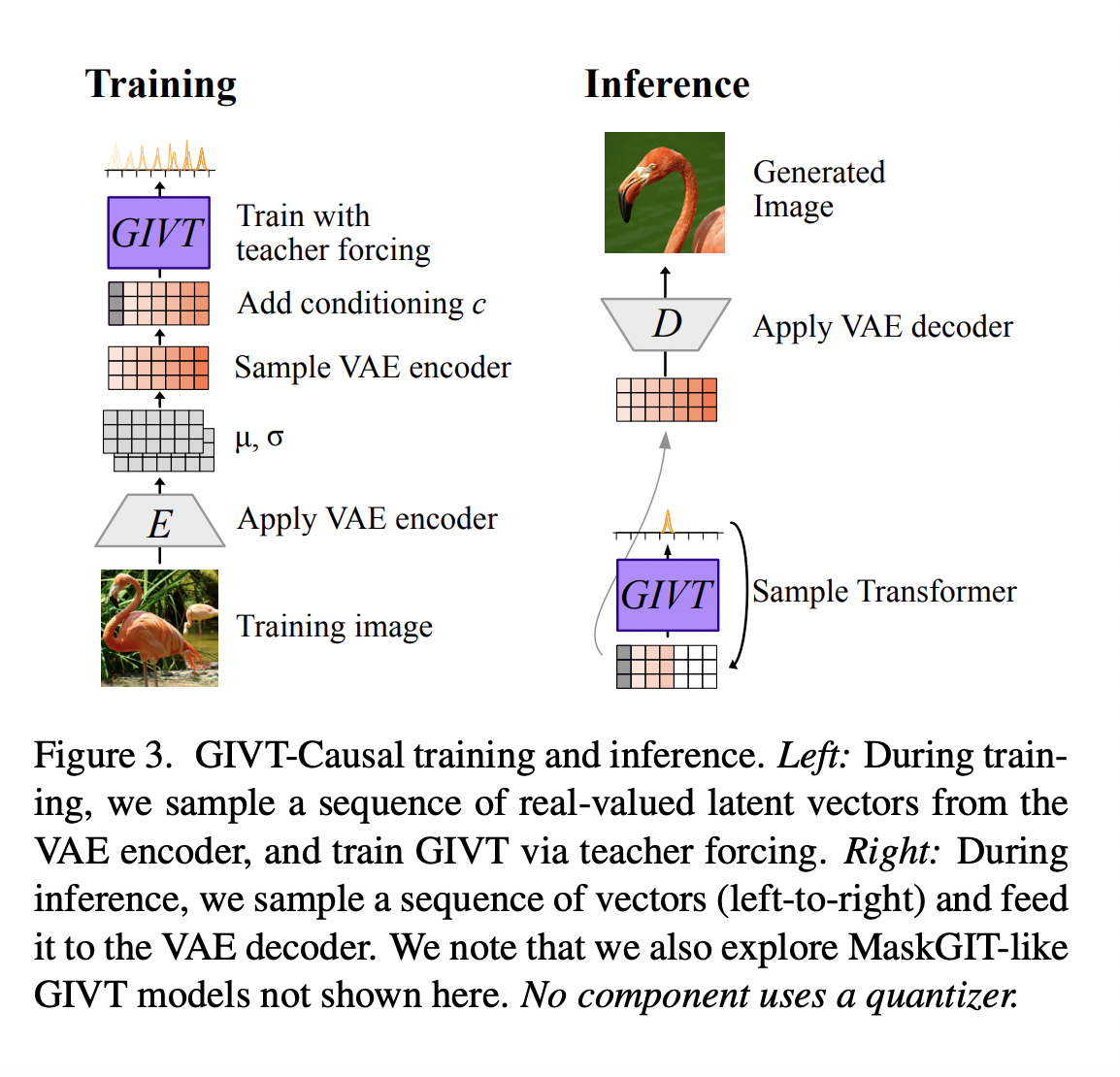
Using reinforcement learning from scratch to teach a computer to play Tic-Tac-Toe Image by author (created with ChatGPT)It appears that everyone in the AI sector is currently honing their Reinforcement Learning (RL) skills, especially in Q-learning, following the recent rumours about OpenAI’s new AI model, Q* and I’m joining in too. However, rather than speculating…