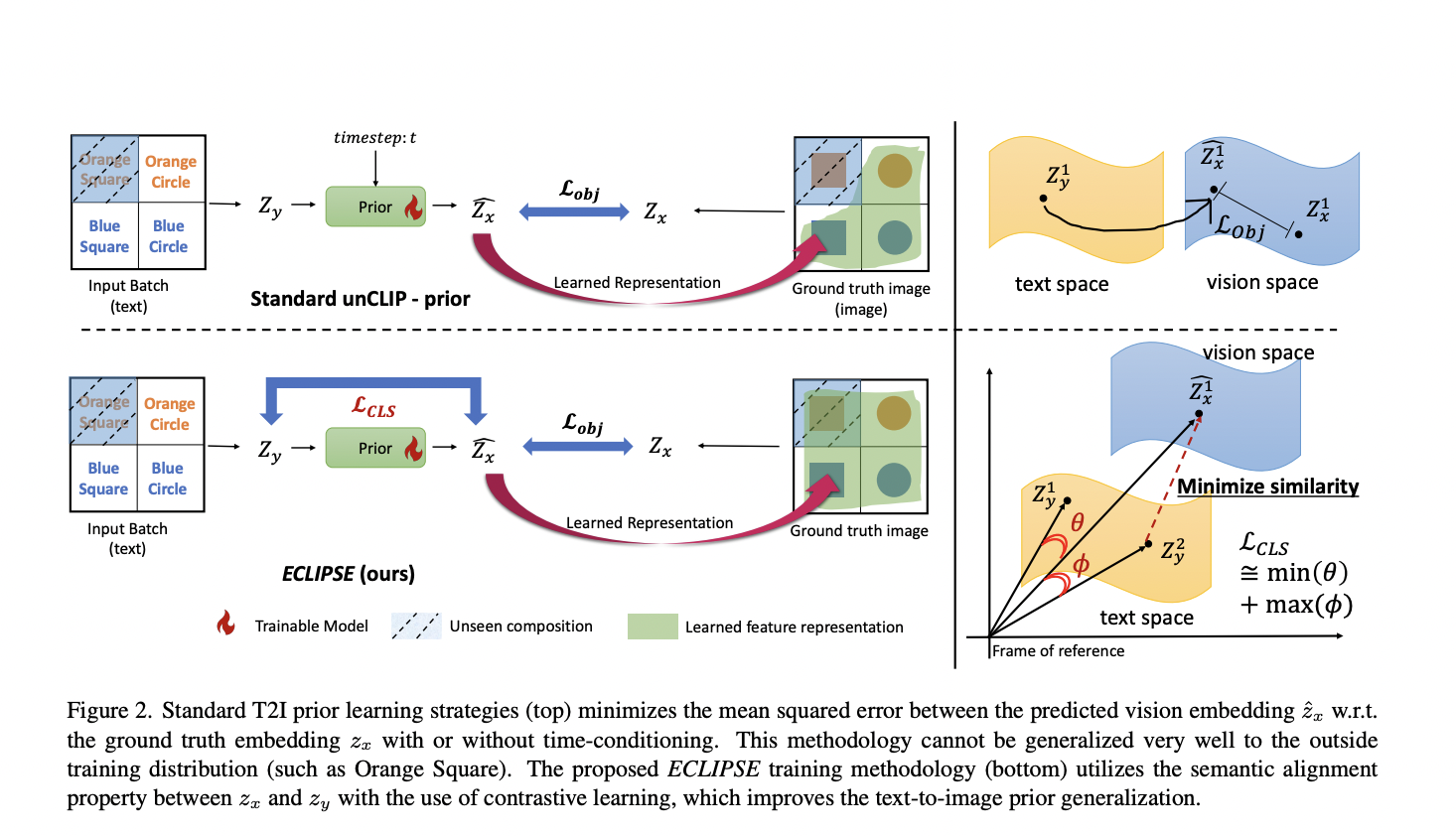
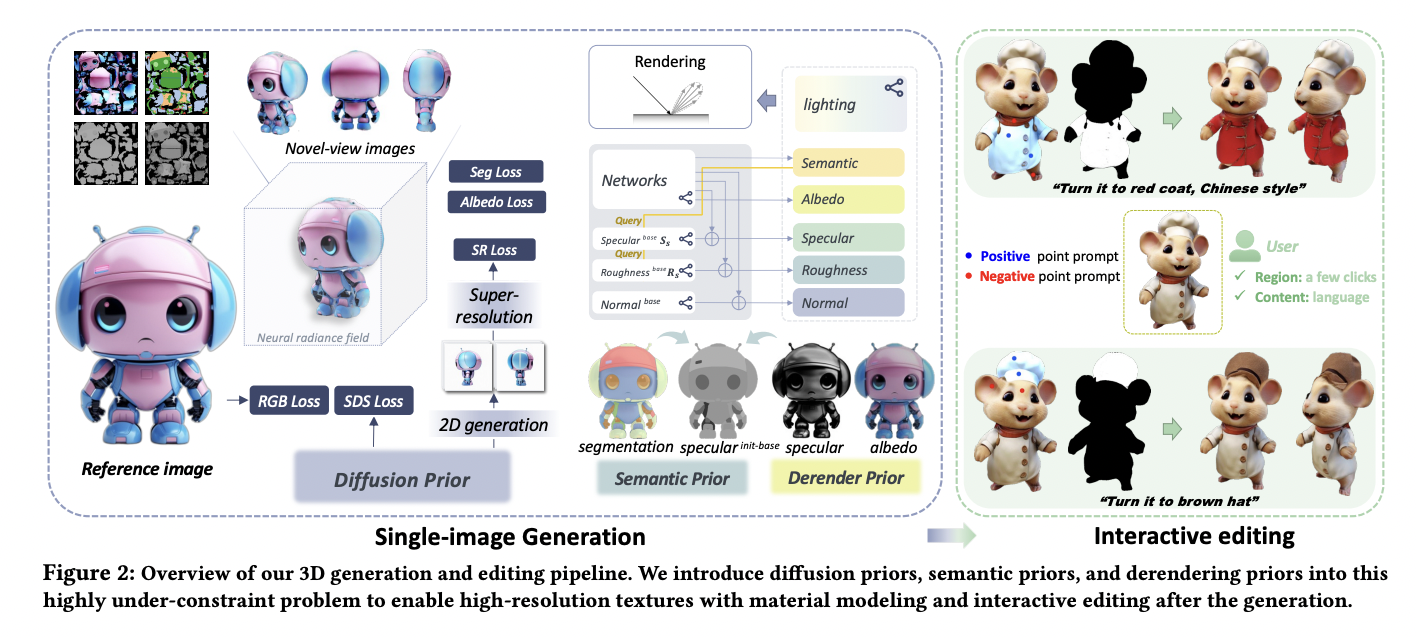
Diffusion models have shown to be very successful in producing high-quality photographs when given text suggestions. This paradigm for Text-to-picture (T2I) production has been successfully used for several downstream applications, including depth-driven picture generation and subject/segmentation identification. Two popular text-conditioned diffusion models, CLIP models and Latent Diffusion Models (LDM), often called Stable Diffusion, are essential…