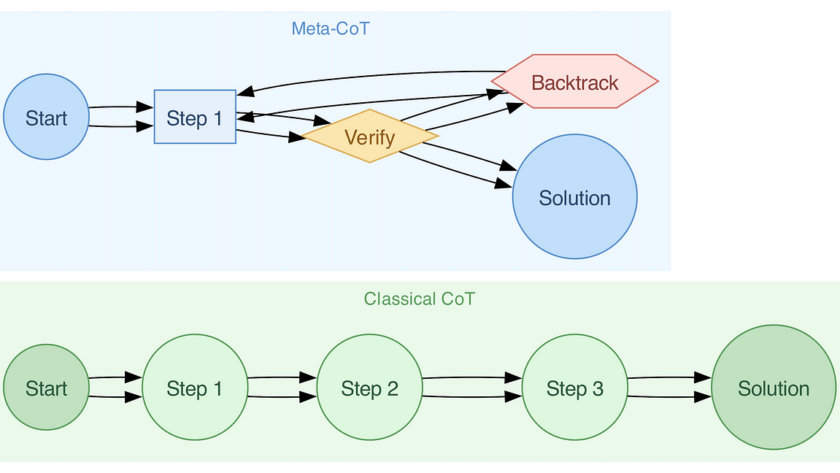
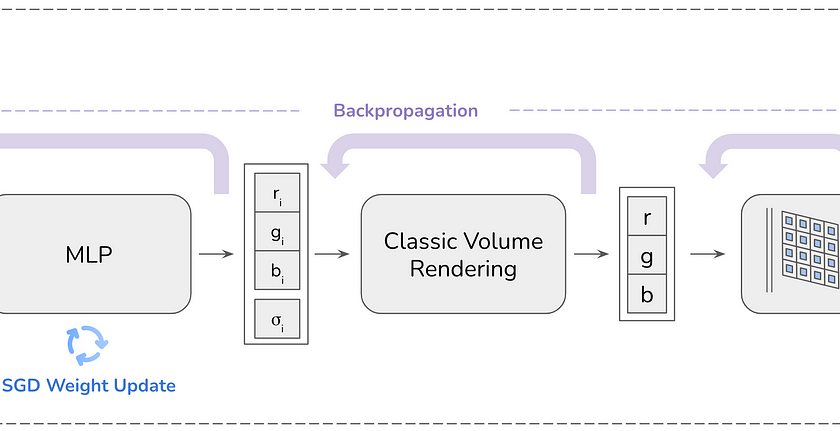
Pre-trained vision models have been foundational to modern-day computer vision advances across various domains, such as image classification, object detection, and image segmentation. There is a rather massive amount of data inflow, creating dynamic data environments that require a continual learning process for our models. New regulations for data privacy require specific information to be…